G1 Humanoid Whole-Body Controller
Oct 26, 2025
·
2 min read
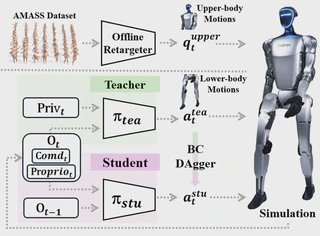
A two-stage learning pipeline for humanoid robot locomotion: Teacher Policy (RL) trained with privileged information in simulation, and Student Policy (IL) distilled from teacher using only proprioceptive observations.
Overview
This project implements a comprehensive learning pipeline for humanoid robot locomotion control:
- Teacher Policy (RL): Trained with privileged information in simulation
- Student Policy (IL): Distilled from teacher using only proprioceptive observations
- Upper-body Motion Retargeting: Integration with AMASS dataset for natural movements
- Real Robot Deployment: Robust control on physical G1 humanoid
Simulation at IsaacSym
Real-world Robot Deployment
Preview: Stable Manipulation
Technical Details
Two-Stage Training Pipeline
This project uses a two-stage approach:
- Teacher Policy: Trained with privileged information in simulation (RL)
- Student Policy: Distilled from teacher using only proprioceptive observations (IL)
Stage 1: Teacher Training (Reinforcement Learning)
Observations (60-dim):
- Angular velocity (3): IMU gyroscope data
- Projected gravity (3): IMU accelerometer projected to body frame
- Command (7):
- Linear velocity (x, y)
- Angular velocity (z)
- Target height
- Body orientation (roll, pitch, yaw)
- Joint positions (15): Legs + waist joint angles
- Joint velocities (15): Legs + waist joint speeds
- Last actions (15): Previous target positions
- Privileged information (2): Feet contact states (left, right)
Actions (15-dim):
- Target joint positions for legs + waist
Training:
- Algorithm: PPO (Proximal Policy Optimization)
- Environment: Isaac Sim with terrain curriculum
- Upper-body control: Retargeted AMASS motions (offline, not part of policy output)
- Lower-body control: Learned by teacher policy
- Reward: Track commands while maintaining stability
Stage 2: Student Training (Imitation Learning)
Observations (116-dim):
- Current observation (58-dim):
- Angular velocity (3), projected gravity (3)
- Command (7)
- Joint positions (15), joint velocities (15)
- Last actions (15)
- Note: No privileged information (feet contact)
- Previous observation (58-dim): Same structure, one timestep earlier
- Total: 116-dim with temporal history
Actions (15-dim):
- Target joint positions for legs + waist (same as teacher)
Training:
- Methods: Behavioral Cloning (BC) or DAgger
- Data source: Demonstrations from teacher policy in simulation
- Objective: Match teacher’s actions using only proprioceptive feedback
Architecture:
- MLP: 116 → 512 → 256 → 128 → 15
- Activation: ELU
Deployment Pipeline
Real Robot Control Loop (20ms):
- State Feedback: Robot SDK2 publishes joint states and IMU data
- Observation Construction: Build 58-dim current observation from sensor data + command
- History Update: Maintain 2-step observation buffer (current + previous)
- Policy Inference: Student policy outputs 15-dim target joint positions
- Command Execution: Send targets to motors with PD gains (kp/kd)
Key Features:
- Temporal awareness via observation history (2 steps)
- JIT-compiled policy for fast inference
- PD control for robust position tracking